Custom Markup Language Editor & Parser
Independent Software Developer
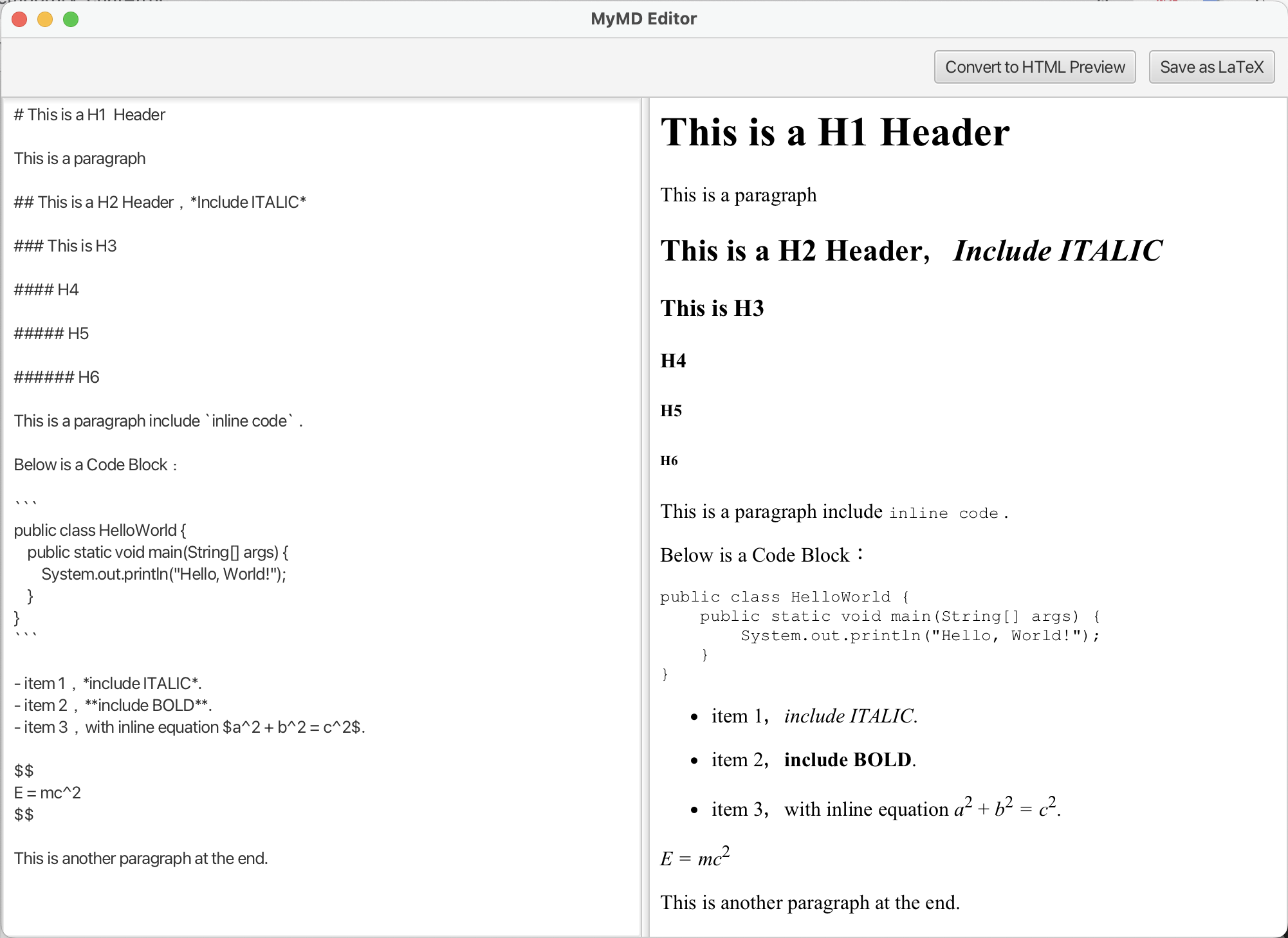
This project was born from a personal need for a tool that blends the simplicity and speed of Markdown with the professional typesetting and citation capabilities of LaTeX. To fill this gap, I independently designed and developed MyMD, a custom markup language, along with its dedicated desktop editor.
The application's core is a compiler front-end built with ANTLR, which accurately parses MyMD source into an Abstract Syntax Tree (AST). Pivoting from an initial, unstable regex-based prototype, the current architecture uses the Visitor pattern to convert the AST into a Pandoc-compatible JSON format. This decouples the parser from the back-end, enabling robust and seamless export to HTML and LaTeX. The entire desktop application was built from the ground up using JavaFX and follows the MVVM architecture to ensure a clean, testable, and extensible codebase, with reliability backed by a suite of JUnit 5 unit tests.
Currently, the project is a Minimum Viable Product (MVP) with a live-preview editor. The long-term vision is to evolve it from a simple GUI into a full-featured Integrated Development Environment (IDE).
Technologies: Java, JavaFX, ANTLR, MVVM, JUnit 5, Maven, Pandoc